
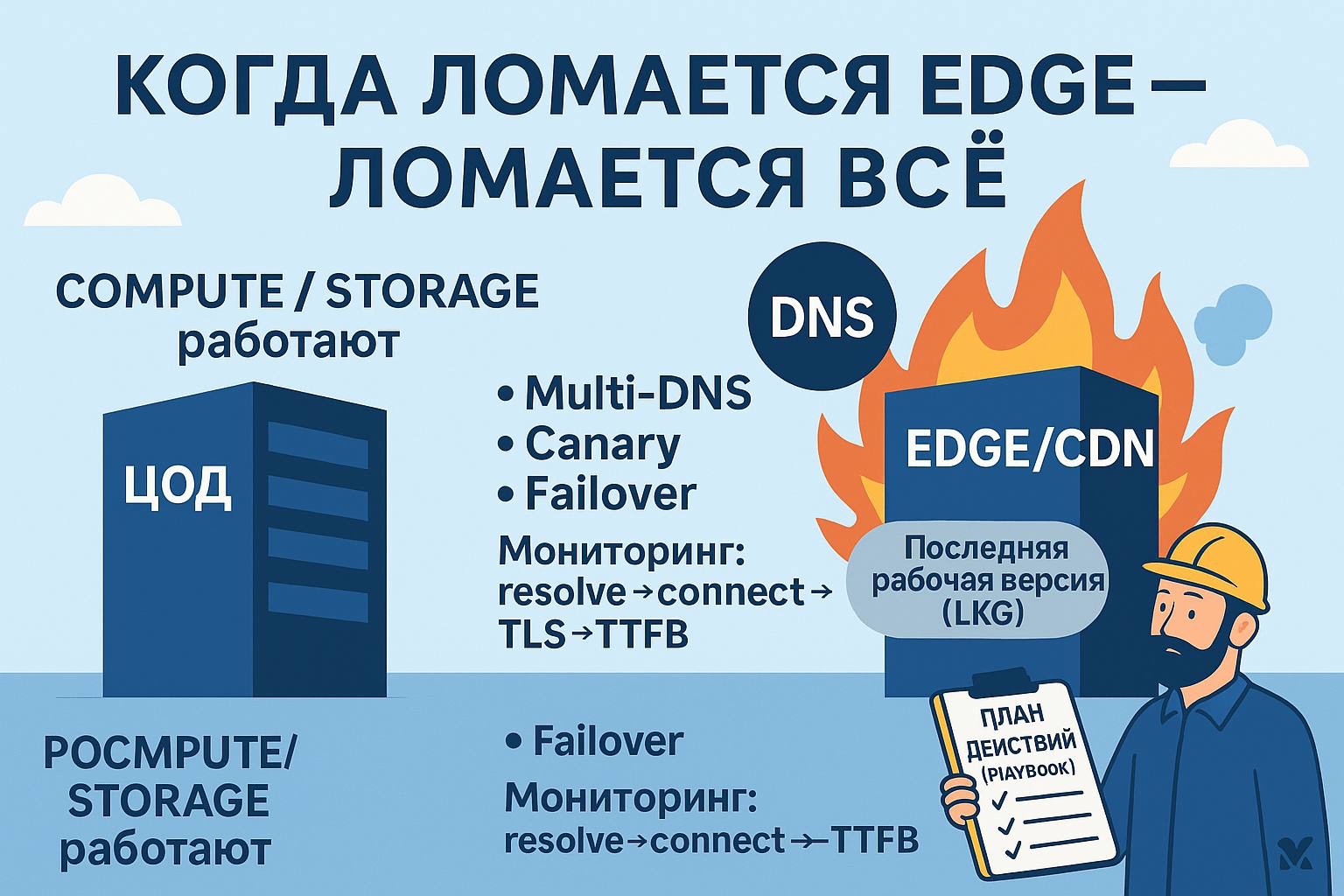
Вот мой взгляд — как DevOps/SRE, которому приходилось проектировать системы с учётом именно таких отказов, — почему «трафиковый слой» (DNS, edge, маршрутизация) заслуживает той же строгости, что и compute и storage, и какие практики я применяю в проде.
29 октября 2025 у Microsoft Azure произошёл глобальный сбой, связанный с Azure Front Door (AFD). Microsoft заблокировала конфигурационные изменения, перевела портал Azure мимо AFD и раскатила по миру конфигурацию «last known good». Хронология и обзоры: The Verge, AP, Reuters и официальный статус-лог Microsoft.
Источники:
• Microsoft Azure status history: https://azure.status.microsoft/en-us/status/history/
• The Verge: https://www.theverge.com/news/809142/microsoft-azure-xbox-365-is-down-outage
• AP: https://apnews.com/article/0deffbd09c09ca4640c2f5452a9e483e
• Reuters: https://www.reuters.com/business/alaska-airlines-says-website-app-down-2025-10-29/
Неделей раньше, 20 октября 2025, AWS пережил крупный инцидент в us-east-1, вызванный путями резолвинга DNS, что задело DynamoDB и множество зависящих сервисов. Публичные разборы и AWS Health указывают на центральную роль DNS.
Источники:
• AWS Health: https://health.aws.amazon.com/health/status?eventID=arn%3Aaws%3Ahealth%3Aus-east-1%3A%3Aevent%2FMULTIPLE_SERVICES%2FAWS_MULTIPLE_SERVICES_OPERATIONAL_ISSUE%2FAWS_MULTIPLE_SERVICES_OPERATIONAL_ISSUE_BA540_514A652BE1A
• The Verge: https://www.theverge.com/news/802486/aws-outage-alexa-fortnite-snapchat-offline
• Cisco ThousandEyes: https://www.thousandeyes.com/blog/aws-outage-analysis-october-20-2025
• The Guardian: https://www.theguardian.com/technology/2025/oct/24/amazon-reveals-cause-of-aws-outage
История рифмуется: у Azure DNS уже был глобальный инцидент 1 апреля 2021. Триггер другой, урок тот же — DNS остаётся системной «узкой горловиной».
• Обзор: https://www.reddit.com/r/sysadmin/comments/mjuemp/rca_azure_dns_outage_1st_april/
Что я изменил в своей практике
Без единственного провайдера на уровне делегирования
• Два провайдера авторитативного DNS с идентичными зонами, безопасными TTL и автосинхронизацией. Health-чеки независимы от вендора. Не связываю логику failover с тем же вендором, что управляет CDN/edge.
• Если использую Route 53 или Azure DNS, держу второй независимый публичный DNS, способный быстро принять NS-делегирование. Разделение обязанностей на edge
• CDN/WAF и авторитативный DNS — у разных вендоров. Если control plane CDN «сломал» конфиг, DNS всё ещё может увести трафик в обход. • Держу минимальный «break-glass» путь управления: сырой HTTPS за отдельным anycast-провайдером и отдельными сертификатами. Active-active по умолчанию
• Сервисы запущены минимум в двух локациях, с реплицированными бэкапами и синтетическими зондами из разных сетей. Failover не сценарий на бумаге — он всегда включён.
• Состояние спроектировано на терпимость: дренаж очередей, идемпотентные воркеры, фичефлаги, развязывающие фронт от записей в бэкенд. SLO на уровне трафика и канарейки
• Меряю успех на edge: время DNS-резолва, TCP-коннекта, TLS-рукопожатия, TTFB, а не только 200/OK от origin.
• Все изменения в edge/CDN — через поэтапный rollout и канареечные скоупы с быстрым откатом. • Референсы: Google SRE — https://sre.google/workbook/index/ и https://sre.google/sre-book/service-best-practices/ Операционные ограждения
• Заморозки в чувствительные периоды, линт и юнит-тесты для CDN/DNS-конфигов, хранение артефактов Last Known Good, режим read-only и деградация на уровне фич.
• Отдельные политики алёртов: «compute ок, edge не ок» и «edge ок, origin деградирует».
Практический чек-лист
Authoritative DNS
• Два независимых провайдера под вашим NS-делегированием.
• Автосинх зон; прагматичные TTL (120–300 с для edge-записей, выше для DS/MX).
• Health-чеки вне единого control plane.
Recursive/Resolver
• Свои кэширующие резолверы для egress + разнообразные апстримы (Quad9, Cloudflare, Google) с policy-routing.
• Мониторинг SERVFAIL/NXDOMAIN и гистограмм задержек по резолверам.
Edge/CDN
• Иной вендор, чем у DNS.
• Канарейте каждое правило. Храните и помечайте LKG-конфиги.
• Прямой доступ к origin (allow-list) и запасной anycast-вход, обходящий основной CDN.
Failover
• Active-active с взвешиванием трафика. Прогревайте «холодные» пути.
• Ежемесячно тестируйте DNS-переключения. Проверяйте липкость сессий и cookie-домены.
Observability
• Глобальные синтетические проверки: resolve → connect → TLS → HTTP.
• Дашборды по «четырём золотым сигналам» на edge. Алёрты по бюджету ошибок, привязанному к пользовательским SLO.
Degradation
• Фичефлаги для тяжёлых эндпойнтов. Кэшированные/статические фоллбэки. Read-only для критичных CRUD.
Runbooks
• «AFD/CDN config bad»: freeze, откат к LKG, смена весов трафика, статус-апдейты, троттлинг фич.
• «DNS bad»: смена NS или переключение первичного провайдера; скрипты для API регистратора готовы.
Почему это важно
Октябрьские инциденты — сначала AWS, затем Azure — не про «павшие VM». Это про конфигурации и control plane трафикового слоя. Когда edge маршрутизирует неверно или DNS «уходит вбок», ваши идеальные реплики баз данных не успевают помочь. Проектирование под такие отказы — новая норма.
Дополнительно:
• Cisco ThousandEyes об AFD: https://www.thousandeyes.com/blog/microsoft-azure-front-door-outage-analysis-october-29-2025
• Независимые разборы триггера: https://blog.senthorus.ch/posts/azure_outage/ и https://breached.company/microsofts-azure-front-door-outage-how-a-configuration-error-cascaded-into-global-service-disruption/
Если нужен конкретный план внедрения — multi-DNS с автосинхом, канареечные пайплайны для edge/CDN, глобальная синтетика и active-active — поделюсь Terraform/GitOps-паттернами и плейбуком тестового cutover под ваш стек.
Добавить комментарий